CUDA backendlink
IREE is being designed with re-targetability as a core goal: it should be possible to use IREE to target a broad spectrum of power regimes, from embedded systems to distributed clusters; and it should be possible to extend IREE to target new back-ends without having to reinvent the wheel each time.
To explore this, we recently branched out from our initial focus on low-latency mobile deployments with a goal of using IREE to target data center workloads on Nvidia CUDA. This post describes how we quickly brought up a CUDA back-end for IREE and used it to train BERT, then shares some metrics and next steps.
Bring uplink
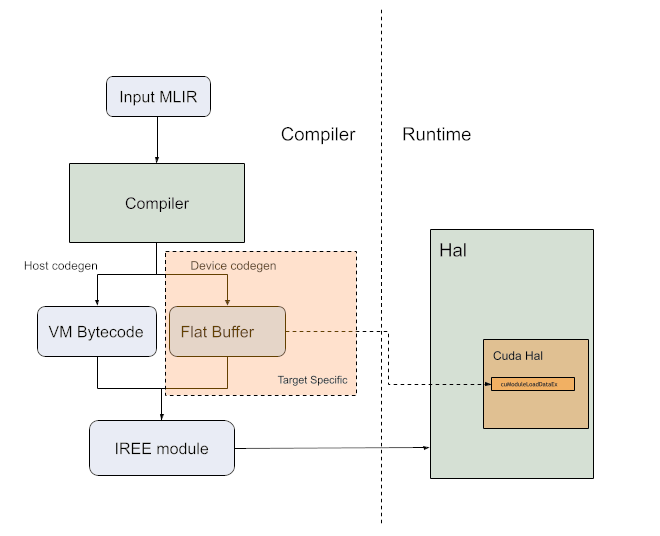
HAL supportlink
IREE has a HAL API that abstract all the targets behind a common interface. The first step to supporting a CUDA target was to map the HAL API onto CUDA. We use the CUDA driver API to reduce dependencies and be closer to the hardware. The HAL API is based on other GPU APIs like Vulkan and Metal, so it was a natural fit for CUDA. The HAL API exposes memory allocations, basic fill and memset commands, kernel dispatch, and general command buffer handling. The original implementation uses the CUDA graph API as a graph maps naturally to command buffers. There is also an implementation using CUDA streams for comparison.
HAL exposes an API that can be tested independently, even if we are not able to create CUDA kernels yet we can test a large portion of the CUDA driver using CTS tests. Those can be run to make sure a system has the required CUDA support.
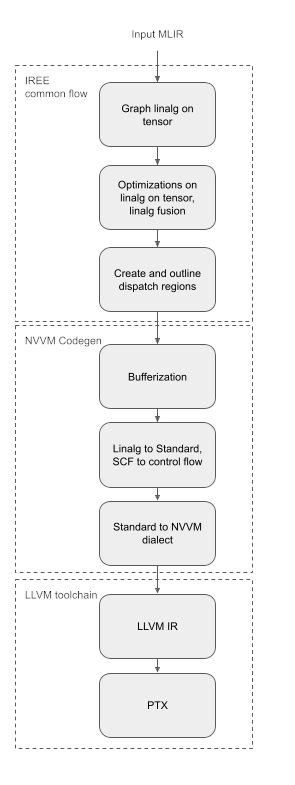
Compiler supportlink
CUDA has an open source backend in LLVM generating PTX that we are leveraging. Therefore IREE can create NVVM (CUDA LLVM variant) and use LLVM's backend to generate PTX. The CUDA driver will do the "last mile compilation" at runtime to convert PTX into the GPU's native ISA.
IREE compiler pipeline starts from linalg with tensor operands. A large part of the compiler is independent of the target.
The linalg on tensor representation of the graph is broken up into dispatch regions that are processed by NVVM Codegen. A simple implementation of the compiler is to run bufferization and convert linalg to standard followed by conversion to NVVM/LLVM. Most of those transformation can re-use upstream MLIR transformations and share it with any other backend targeting LLVM IR. Leveraging MLIR conversion to LLVM will allow us to quickly go from a simple "hello world" to supporting full models.
IREE code generation is based on MLIR infrastructure so each step can easily be tested independently using the MLIR lit framework.
FlatBuffer definitionlink
Kernels are encoded in a FlatBuffer containing the PTX code as well as the workgroup size to use for the dispatch. This allows serialization of the kernels in the IR, it is then de-serialized by the HAL layer.
table CUDAExecutableDef {
// A map of entry point ordinals to string names as used in the shader
// library.
entry_points:[string];
// Block sizes for each entry point.
block_sizes:[CUDABlockSize];
// PTX string of the module.
ptx_image:string;
}
Hello worldlink
Together those 3 steps are enough to provide most of the functionality and we can now successfully compile full models.
To reproduce running a simple op end to end through CUDA backend, save the
following mlir in /tmp/add.mlir and then run the following given commands:
func.func @add(%arg0: tensor<4xf32>, %arg1: tensor<4xf32>) -> tensor<4xf32> {
%0 = tensor.empty() : tensor<4xf32>
%1 = linalg.generic {
indexing_maps = [
affine_map<(d0) -> (d0)>, affine_map<(d0) -> (d0)>, affine_map<(d0) -> (d0)>], iterator_types = ["parallel"]}
ins(%arg0, %arg1 : tensor<4xf32>, tensor<4xf32>)
outs(%0 : tensor<4xf32>) {
^bb0(%in: f32, %in_0: f32, %out: f32):
%2 = arith.addf %in, %in_0 : f32
linalg.yield %2 : f32
} -> tensor<4xf32>
return %1 : tensor<4xf32>
}
# First compile into a VM bytecode module.
$ ../iree-build/tools/iree-compile \
--iree-hal-target-device=cuda \
/tmp/add.mlir \
-o /tmp/add.vmfb
# Run the module through CUDA HAL backend.
$ ../iree-build/tools/iree-run-module \
--device=cuda \
--module=/tmp/add.vmfb \
--function=add \
--input="4xf32=[1 2 3 4]" \
--input="4xf32=[2 2 2 2]"
EXEC @add
4xf32=3 4 5 6
Performancelink
Now that we have enabled functionality we need to look at the performance. Once again we can leverage existing MLIR transformations to speed up the development work.
Tiling and distributionlink
The first obvious step to get efficient code on CUDA is to make sure we distribute the work on enough blocks and threads to fill up the GPU. At the time of bring up not all ops were being tiled and distributed in the common IREE layer. During dispatch region creation we apply tile and fuse which will distribute the work into a set of workgroups that are mapped to CUDA blocks.
At the beginning of the code generation we look at the dispatch region and decide on the tile size for a workgroup. For CUDA we also decide the number of threads per block. We will then have a pass tiling the ops in the dispatch region a second time to distribute the work onto threads within the block.
At this stage the IR looks like the following:
%8 = "gpu.thread_id"() {dimension = "x"} : () -> index
%9 = affine.apply affine_map<()[s0] -> (s0 * 4)>()[%8]
%10 = memref.subview %in0[%9] [4] [1] : memref<128xf32, affine_map<(d0)[s0] -> (d0 + s0)>> to memref<4xf32, affine_map<(d0)[s0] -> (d0 + s0)>>
%11 = memref.subview %in1[%9] [4] [1] : memref<128xf32, affine_map<(d0)[s0] -> (d0 + s0)>> to memref<4xf32, affine_map<(d0)[s0] -> (d0 + s0)>>
%12 = memref.subview %out[%9] [4] [1] : memref<128xf32, affine_map<(d0)[s0] -> (d0 + s0)>> to memref<4xf32, affine_map<(d0)[s0] -> (d0 + s0)>>
linalg.generic {
indexing_maps = [affine_map<(d0) -> (d0)>,
affine_map<(d0) -> (d0)>,
affine_map<(d0) -> (d0)>],
iterator_types = ["parallel"]}
ins(%10, %11 :
memref<4xf32, affine_map<(d0)[s0] -> (d0 + s0)>>,
memref<4xf32, affine_map<(d0)[s0] -> (d0 + s0)>>)
outs(%12 : memref<4xf32, affine_map<(d0)[s0] -> (d0 + s0)>>) {
^bb0(%arg1: f32, %arg2: f32, %arg3: f32):
%13 = addf %arg1, %arg2 : f32
linalg.yield %13 : f32
}
Vectorizationlink
Even though GPUs execute most operations as scalar, memory operations are optimized to access 128 bits of data per thread. Therefore it is critical to vectorize load/store operations. After tiling to a size we vectorize the IR to get vector read/write mapping to load4/store4. This significantly improves the memory access pattern of the code generated.
This convert the previous IR to:
%8 = "gpu.thread_id"() {dimension = "x"} : () -> index
%9 = affine.apply affine_map<()[s0] -> (s0 * 4)>()[%8]
%10 = memref.subview %in0[%9] [4] [1] : memref<128xf32, affine_map<(d0)[s0] -> (d0 + s0)>> to memref<4xf32, affine_map<(d0)[s0] -> (d0 + s0)>>
%11 = memref.subview %in1[%9] [4] [1] : memref<128xf32, affine_map<(d0)[s0] -> (d0 + s0)>> to memref<4xf32, affine_map<(d0)[s0] -> (d0 + s0)>>
%12 = memref.subview %out[%9] [4] [1] : memref<128xf32, affine_map<(d0)[s0] -> (d0 + s0)>> to memref<4xf32, affine_map<(d0)[s0] -> (d0 + s0)>>
%13 = vector.transfer_read %10[%c0], %cst {in_bounds = [true]} : memref<4xf32, affine_map<(d0)[s0] -> (d0 + s0)>>, vector<4xf32>
%14 = vector.transfer_read %11[%c0], %cst {in_bounds = [true]} : memref<4xf32, affine_map<(d0)[s0] -> (d0 + s0)>>, vector<4xf32>
%15 = addf %13, %14 : vector<4xf32>
vector.transfer_write %15, %12[%c0] {in_bounds = [true]} : vector<4xf32>, memref<4xf32, affine_map<(d0)[s0] -> (d0 + s0)>>
Shared memory optimizationlink
Nvidia GPUs have a fast shared memory that needs to be leveraged to optimize cases where we may be memory bound and have the potential to re-use memory reads.
For operations like GEMM using shared memory gives us a significant speed up. We leverage memory promotion, vector distribution and software pipelining transformations from MLIR to generate efficient copies from global to shared memory that can be interleaved with the compute work.
Optimization pipelinelink
Those different transformations compose to this flow:
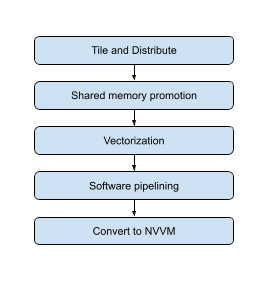
The full dump step by step of a linalg.matmul operation can be found here.
Results and next stepslink
GEMMlink
We compare the performance of a single GEMM operation to highly optimized library cuBLAS using mmperf framework.
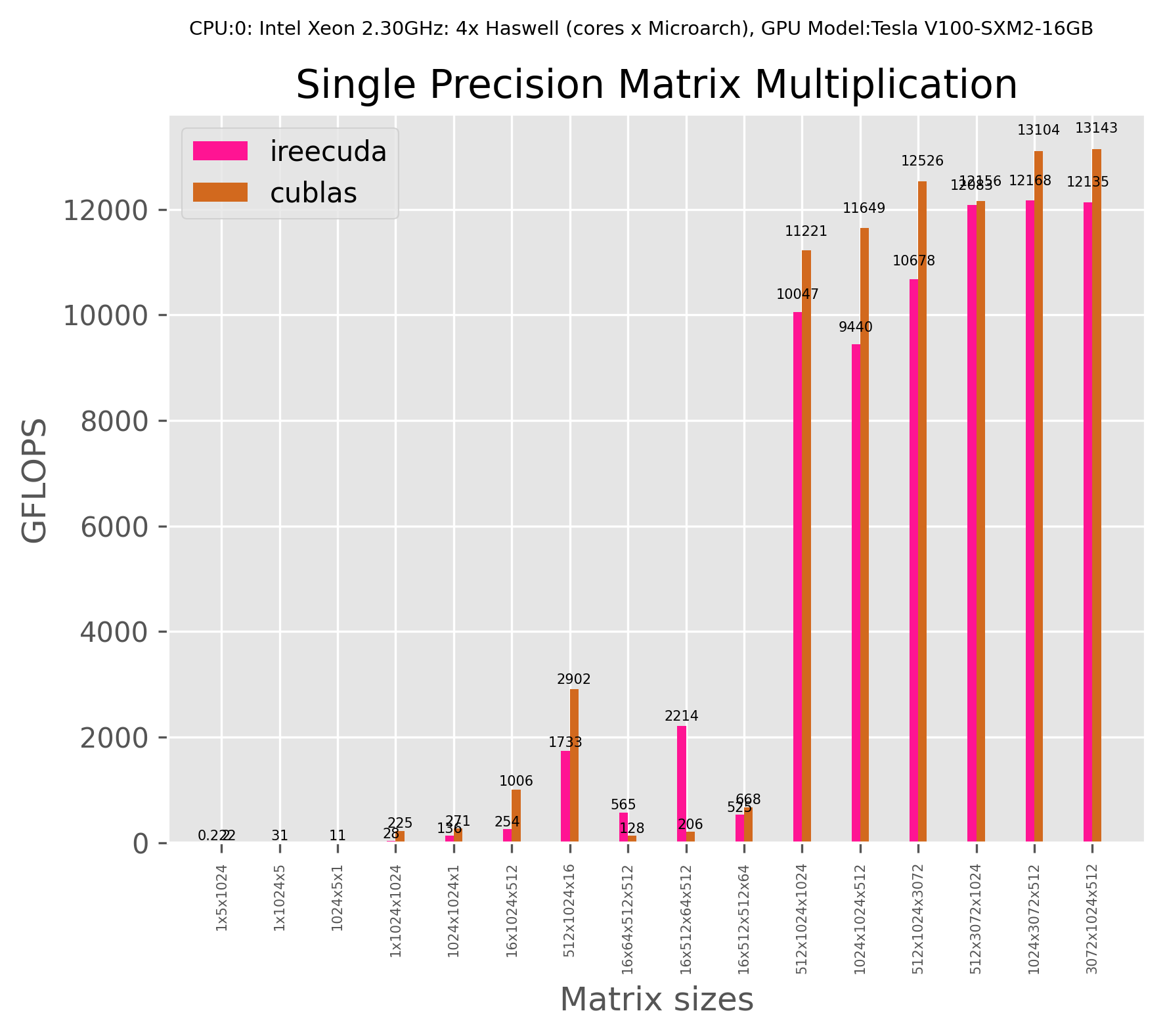
The graph can be re-produced based on instructions on mmperf
Future worklink
Nod.ai has contributed an experimental HAL module for ROCM that allows us to re-use the compiler parts to support ROCM, more support is going to be added in the future.
Several performance improvements are still under progress, including optimizing the runtime allocator to reduce the host-side overhead and tuning tile sizes based profiling.
Several models are running and we will publish more detailed benchmark results in the near future.